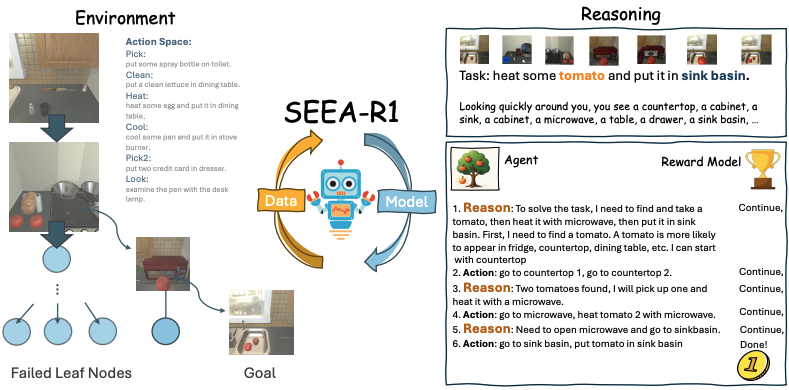
Self-evolution, the ability of agents to autonomously improve their reasoning and behavior, is essential for the embodied domain with long-horizon, real-world tasks. Despite current advancements in reinforcement fine-tuning (RFT) showing strong performance in enhancing reasoning in LLMs, its potential to enable self-evolving embodied intelligence with multi-modal interactions remains largely unexplored. Specifically, reinforcement fine-tuning faces two fundamental obstacles in embodied settings: (i) the lack of accessible intermediate rewards in multi-step reasoning tasks limits effective learning signals, and (ii) reliance on hand-crafted reward functions restricts generalization to novel tasks and environments. To address these challenges, we present Self-Evolving Embodied Agents-R1, SEEA-R1, the first RFT framework designed for enabling the self-evolving capabilities of embodied agents. Specifically, to convert sparse delayed rewards into denser intermediate signals that improve multi-step reasoning, we propose Tree-based group relative policy optimization (Tree-GRPO) integrates Monte Carlo Tree Search into GRPO. To generalize reward estimation across tasks and scenes, supporting autonomous adaptation and reward-driven self-evolution, we further introduce Multi-modal Generative Reward Model (MGRM). To holistically evaluate the effectiveness of SEEA-R1, we evaluate on the ALFWorld benchmark, surpassing state-of-the-art methods with scores of 85.07% (textual) and 36.19% (multi-modal), outperforming prior models including GPT-4o. SEEA-R1 also achieves scores of 80.3% without environmental reward, surpassing all open-source baselines and highlighting its scalability as a self-evolving embodied agent. Additional experiments and qualitative analysis further support the potential of SEEA-R1 for future research in scalable embodied intelligence.

The framework drives continuous improvement through an iterative loop of two core cycles as follows: 1. Data Evolution: The Policy Model interacts with the environment via MCTS from an initial state to generate the experience dataset, containing trajectories with derived Q-values, ground truth rewards from the environment, and rewards from the current Reward Model. 2. Model Evolution: The collected data is used to update both models: (a) The Policy Model to predict actions and (b) The Reward Model to predict categorical outcomes. Refined models from Model Evolution then drive the next Data Evolution iteration, enabling continuous self-evolution.

r.Q.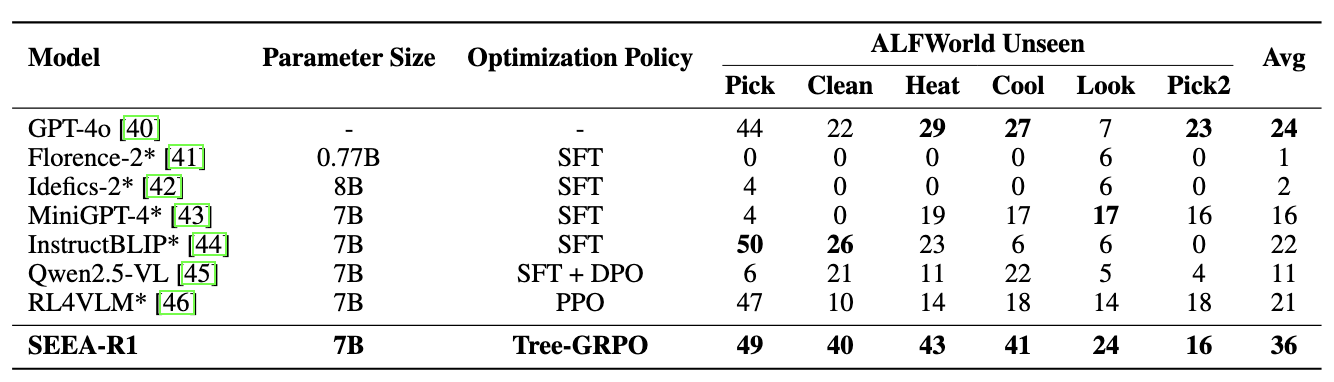
MMBench is a multimodal benchmark that subdivides reasoning and perception capabilities into six Level-2 dimensions: Logic Reasoning (LR), Attribute Reasoning (AR), Relation Reasoning (RR) for Reasoning, and Fine-Grained Perception-Single Instance (FP-S), Fine-Grained Perception-Cross Instance (FP-C), and Coarse Perception (CP) for Perception.
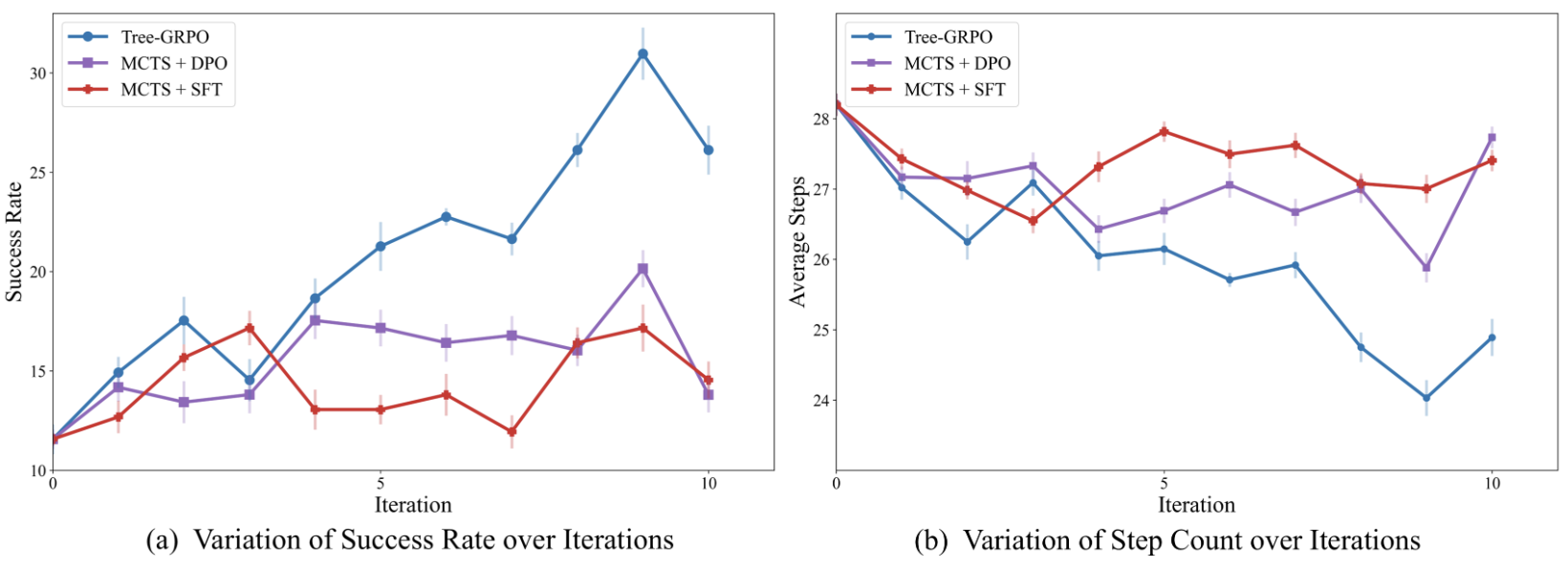
Performance comparison of SEEA-R1 using different optimization algorithms on ALFWorld over training iterations.
To evaluate the generalization ability of our embodied agents beyond the training environment, we introduce EmbodiedEval as an out-of-distribution benchmark. EmbodiedEval tests MLLMs as embodied agents across diverse tasks—including Attribute Question Answering (AttrQA), Spatial Question Answering (SpatialQA), Navigation, Object Interaction, and Social Interaction—within 125 realistic 3D scenes. It provides a comprehensive assessment of agent capabilities in previously unseen scenarios. This setup enables us to measure generalization under significant domain shifts compared to the ALFWorld environment. We analyze the impact of different control strategies on performance, using key metrics such as overall accuracy, which reflects the percentage of fully completed tasks.
Task:Identify an object that is taller than 1 m.
Result:Succeed
Task:How many antiques are there on the glass table in the living room? Be careful not to mistake food for antiques.
Result:Succeed
Task:Are there more flower pots in the living room or the bedroom?
Result:Failed
Task:Position yourself in front of the instrument that can be used for playing music.
Result:Succeed
Task:Walk through the kitchen, enter the bedroom, and draw near to the switch handle next to the orange floor lamp.
Result:Succeed
Task:Walk towards the tallest tree in the yard.
Result:Failed
Task:Pick up the red notebook on the side table in the living room.
Result:Succeed
Task:Turn on the TV.
Result:Succeed
Task:Is there an egg inside the fridge?
Result:Failed
Task:Which has a larger area: the carpet in the bedroom or the rug in the bathroom?.
Result:Succeed
Task:Are all the chairs around the round table in the kitchen the same height?.
Result:Succeed
Task:Compare the size of the television in the living room to the mirror in the bedroom.
Result:Failed